
开云(中国)Kaiyun·官方网站 - 登录入口
你的位置:开云(中国)Kaiyun·官方网站 - 登录入口 > 新闻中心 >
发布日期:2026-03-30 15:36 点击次数:77

DeepSeek 的压力开yun体育网,终于照旧传递到了黄仁勋身上。
北京时辰 1 月 27 日晚,英伟达好意思股股价盘前暴跌近 11%,按当前市值 34928 亿好意思元计较,英伟达市值恐将缩水超 3500 亿好意思元。
DeepSeek 所掀翻的低成本大模子历练战术,正在让成本阛阓怀疑,即当用相对较少的算力也能已毕不输于 OpenAI 的模子性能解析时,英伟达所代表的高端算力芯片是否正迎来新的泡沫?
这股担忧心扉正进一步助推着 DeepSeek 的热度攀升。趁着 DeepSeek R1 新模子发布档口,短短一周时辰,到 1 月 27 日,DeepSeek 期骗就拿下了好意思区 App Store 和中国区 App Store 免费榜的双料第一。
值得一提的是,这是初次有 AI 助手类产物超越 OpenAI 的 ChatGPT,且登顶好意思区 App Store。
爆火的用户体验场地,径直导致 DeepSeek 在两天之内接连出现工作宕机征象。继 1 月 26 日出现短时闪崩后,1 月 27 日,DeepSeek 再次轻微出现网页 /API 不可用的工作教唆。官方讲演称,其可能和工作防御、申请收敛等身分筹商。
新模子 DeepSeek R1,无疑是激发这场围绕 DeepSeek 的群众用户大商议的径直导火索。1 月 20 日,DeepSeek 崇拜发布了性能并列 OpenAI o1 完好版的 R1。
在数据越多、恶果越好的 Scaling Law(模子规模定律)触达瓶颈之下,旧年 9 月份,OpenAI 对外发布了新推理模子 o1,后者罗致了 RL(强化学习)的新历练表情,被行业视为是大模子规模的一次"范式升沉"。
但直到 DeepSeek R1 发布之前,国内一众大模子厂商均尚未推出大略对标 OpenAI o1 的模子。DeepSeek 成了第一个攻破 OpenAI 手艺黑匣子的玩家。
更报复的是,比拟 OpenAI 在模子上的闭源,以及 o1 模子付费使用收敛,DeepSeek R1 不仅开源,并且还免费供群众用户无穷调用。
R1 的出现,除了冲破旗舰开源模子只可有科技大厂来鼓吹的行业传悉数鸣以外,还冲破了业内在旧年酿成的另一条共鸣,即通用大模子,正越来越成为一场大厂间的成本比拼游戏。DeepSeek 用不到 OpenAI 十分之一的资源,就作念出了性能堪比 o1 的 R1。
DeepSeek 携一众用户带来的冲击,也曾让一些大厂坐不住了。
首当其冲的是 Meta。一贯被行业视为"大模子开源之王"的 Meta,里面被曝出开动牵铭刻还未发布的 Llama 4,在性能上可能无法赶上 DeepSeek R1。
被拿来全濒临办法 OpenAI,也开动感受到压力。OpenAI CEO 奥特曼不仅通过发布首个智能体 Operator 抢热度,还开动对外剧透起行将上线的 o3-mini 新音讯。
不错想到的是,DeepSeek 掀翻的行业地震,涉及的将不仅仅海外公司,国内大厂也难逃例外。

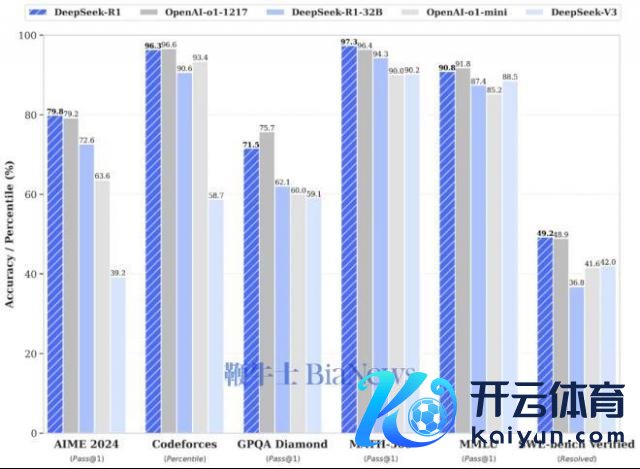
算作一款开源模子,DeepSeek R1 在数学、代码、当然说话推理等任务上的性能,堪称不错并列 OpenAI o1 模子郑再版。
在 AIME 2024 数学基准测试中,DeepSeek R1 得分率为 79.8%,OpenAI o1 的得分率为 79.2%;在 MATH-500 基准测试中,DeepSeek R1 得分率为 97.3%,OpenAI o1 的得分率为 96.4%。
同为推理模子,DeepSeek R1 不同于 OpenAI o1 的手艺关节点,在于其革命的历练门径,如在数据历练设施使用的 R1-Zero 道路,径直刚毅化学习(RL)期骗于基础模子,而无需依赖监督微调(SFT)和已标注数据。
此前,OpenAI 的数据历练相配依赖东谈主工侵略,旗下数据团队以至被提拔成为不同水平的层级,数据量大、标注条款浅显豁确的浅层数据,交给肯尼亚等低价外包劳工,高级第的数据则交给更高教学记号东谈主员,不少齐是历练有素的高校博士。
DeepSeek R1 的径直强化学习道路,就像让一个天才儿童在莫得任何范例和指挥的情况下,地谈通过约束尝试和赢得反应来学习解题。
Perplexity 公司 CEO 阿拉文 · 斯里尼瓦斯评价谈:"需求是发明之母。因为 DeepSeek 必须找到贬责办法,最终它们创造出了更高效的手艺。"
除此以外,在获取高质料数据方面,DeepSeek 也有所革命。
把柄 DeepSeek 官方手艺文档,R1 模子使用数据蒸馏手艺(Distillation)生成的高质料数据,耕作了历练效劳。数据蒸馏指的是通过一系列算法和战术,将原始的、复杂的数据进行去噪、降维、索要等操作,从而得到更为浩繁、灵验的数据。
这亦然 DeepSeek 大略凭借更小参数目,就已毕并列 OpenAI o1 模子性能的一大关节。东谈主工智能众人口磊博士告诉字母榜(ID:wujicaijing),模子参数目大小与最终模子呈现的恶果之间,两者"插足产出并不成正比,而口角线性的……数据多仅仅一个定性,更报复的是进修团队数据清洗的技艺,不然跟着数据增多,数据干扰也将随之变大。"
更报复的是,DeepSeek 是在用不到十分之一的资源基础上,取得的上述收获。
旧年 12 月底发布的 DeepSeek-V3 开源基础模子,性能对标 GPT-4o,但官方先容的历练就本只须 2048 块英伟达 H800,总破耗约 557.6 万好意思元。
算作对比,GPT-4o 模子的历练就本约为 1 亿好意思元,占用英伟达 GPU 量级在万块以上,且是比 H800 性能更强的 H100。
那时,前 OpenAI 联创、特斯拉自动驾驶负责东谈主安德烈 · 卡帕西就发文默示,DeepSeek-V3 级别的技艺,每每需要接近 16000 颗 GPU 的集群。
当前,DeepSeek 官方尚未公布历练推理模子 R1 的完好成本,但官方公布了其 API 订价,R1 每百万输入 tokens 在 1 元 -4 元东谈主民币,每百万输出 tokens 为 16 元东谈主民币。算作对比,OpenAI o1 的运行成本约为前者的 30 倍。
这么的解析也激发 Scale AI 首创东谈主亚历山大 · 王(Alexandr Wang)评价谈,中国东谈主工智能公司 DeepSeek 的 AI 大模子性能约莫与好意思国最佳的模子极度。"昔日十年来,好意思国可能一直在东谈主工智能竞赛中最初于中国,但 DeepSeek 的 AI 大模子发布可能会‘改变一切’。"
a16z 合资东谈主、AI 大模子 Mistral 董事会成员 Anjney Midha 更是发文说谈,从斯坦福到麻省理工,DeepSeek R1 险些整夜之间就成了好意思国顶尖大学研究东谈主员的首选模子。
包括斯坦福大学计较机科学系客座教授吴恩达、微软董事长兼 CEO 萨提亚 · 纳德拉等大佬在内,也齐开动热诚起这款来自中国的新模子。
事实上,这并非 DeepSeek 第一次出圈。在通告组建团队自研大模子以来,DeepSeek 曾两度激发烧议,只不外,之前更多局限在国内。
2023 年 4 月,千亿量化私募巨头幻方量化发布公告,称将调处资源和力量,投身东谈主工智能手艺,提拔新的独处研究组织,探索 AGI(通用东谈主工智能)。
一个月后的 2023 年 5 月,该组织被定名为"深度求索",并发布了首款模子 DeepSeek V1。那时,《财经十一东谈主》报谈称,国内领有特出 1 万枚 GPU 的企业不特出 5 家。而 DeepSeek 即是其中之一,并由此开动得到外界热诚。
及至 2024 年 5 月,DeepSeek 再次借助大模子价钱战一跃成名。那时,DeepSeek 发布了 DeepSeek V2 开源模子,并在行业内率先降价,将推理成本降到每百万 token 仅 1 块钱,约等于 GPT-4 Turbo 的七十分之一。
随后,字节、腾讯、百度、阿里等大厂纷繁降价跟进。中国大模子价钱战由此揭幕。

DeepSeek R1 的出现,进一步向外界评释着,在大模子,尤其是通用大模子方面,创业公司依然有契机。
1 月初,零一万物首创东谈主李开复对外崇拜表态,我方将退出对 AGI 的追寻,畴昔公司主攻中小参数的行业模子。"从买卖角度计议,咱们认为只须大公司能链接作念超大模子。"李开复说谈。
投资东谈主们比李开复更激进。从 2023 年开动,算作金沙江创投主宰合资东谈主的朱啸虎,便认为大模子在毁坏创业,因为模子、算力和数据等三大搭救齐向大厂调处,看不到创业公司的契机,且径直在大模子上作念期骗护城河太低,屡次提醒创业者不要迷信通用大模子。
瞭望成本程浩更是径直认为中国版的 ChatGPT,只会在 5 家公司里产生:BAT+ 字节 + 华为。在程浩看来,创业者只须在具有先发上风的情况下,才有可能跑赢大厂。
恰是因为当初谷歌等海外大厂并不看好 OpenAI 的大说话模子道路,才让 ChatGPT 借助先发势能跑了出来。然则,当下研发大模子也曾成为中国科技大厂的共鸣,以至百度、阿里推分娩物的动作,比创业公司还快。
但在接受暗涌采访中,DeepSeek 首创东谈主梁文锋在讲演与大厂竞争中曾说谈,"大厂细则有上风,但若是不成很快期骗,大厂也不一定能合手续坚合手,因为它更需要看到收场。头部的创业公司也有手艺作念得很塌实的,但和老的一波 AI 创业公司一样,齐要濒临买卖化繁难。"
背靠千亿量化基金的 DeepSeek,在免去资金的黄雀伺蝉外,遴选了一条颇显梦想主义的旅途,即只作念模子研究,不计议买卖变现,且勇猛启动年青东谈主。
在 DeepSeek 的 150 傍边团队中,大多是一帮 Top 高校的应届毕业生、没毕业的博四、博五实习生,以及一些毕业才几年的年青东谈主。
这是梁文锋有意遴选的收场,亦然 DeepSeek 大略抢在大厂前边推出 R1 模子的窍门之一,"若是追求短期运筹帷幄,找现成有陶冶的东谈主是对的。但若是看长久,陶冶就没那么报复,基础技艺、创造性、怜爱等更报复。"梁文锋解释谈。
这也使得 DeepSeek 成了中国大模子创业公司中,唯独一家只作念基础模子、暂不计议买卖化的公司,还要加上一条,即有技艺链接开源旗舰模子的公司。
收场当前,DeepSeek R1 也曾成为开源社区 Hugging Face 高下载量最高的大模子之一,下载量特出 10 万次。

此前,国内以百度首创东谈主李彦宏为代表的一片,坚决认为开源道路打不外闭源道路,且缺少买卖化撑合手的开源模子,会在往后的竞争中差距越拉越大。
但起码从当前来看,DeepSeek R1 的出现,评释靠开源道路依然大略追上大模子头部玩家的脚步,且创业公司依然有技艺鼓吹开源生态发展。
Meta AI 首席科学家杨立昆(Yann LeCun)在评价中就提到,"给那些看到 DeepSeek 的解析后,认为‘中国在 AI 方面正在超越好意思国’的东谈主,你们的解读是错的。正确的解读应该是,‘开源模子正在超越私有模子’。"
在旧年 DeepSeek v3 发布后,梁文锋就曾对外在示,公司畴昔不会像 OpenAI 一样遴选从开源走向闭源,"咱们认为先有一个纷乱的手艺生态更报复。"
毕竟,OpenAI 的陶冶起码阐发了,在颠覆性的手艺眼前,闭源难以酿成实足的护城河,更无法遏止被别东谈主赶超。"是以咱们把价值千里淀在团队上,咱们的共事在这个经过中得到成长,积贮许多 know-how, 酿成不错革命的组织和文化,即是咱们的护城河。"
2020 年发布 GPT-3 时,OpenAI 曾细心公开了模子历练的整个手艺细节。中国东谈主民大学高瓴东谈主工智能学院实行院长文继荣认为,国内许多大模子其实齐有 GPT-3 的影子。
但跟着 OpenAI 在 GPT-4 上一改开源战术,缓缓走向阻滞,一些国产大模子就此失去了可供复制的追逐旅途。
如今,DeepSeek 携开源 R1 的到来,无疑将给国表里大模子玩家在对标 o1 的推理模子研发方面,创建起一条新的鉴戒想路。

DeepSeek 在大模子规模掀翻的这场蝴蝶效应,也曾开动影响到部分大厂。
有 Meta 职工在硅谷匿名八卦共享平台 Blind 上发布音讯称,Meta 的生成式 AI 部门正因 DeepSeek 处于傲气中,以至爆料称尚未发布的新一代开源模子 Llama 4,在基准测试中也曾过期于 DeepSeek。
在外媒的进一步报谈中,Meta 生成式 AI 团队和基础设施团队,正在组建 4 个作战小分队来像素级主张 DeepSeek,有的试图搞明晰 DeepSeek 是若何裁减历练和运行成本的,有的负责研究 DeepSeek 可能使用了哪些数据来历练模子,有的则计议基于 DeepSeek 模子的属性重组 Meta 模子的新手艺。

图源:AI 制作
与此同期,为了饱读励士气,算作 Meta 首创东谈主的扎克伯格,更是放出 2025 年链接扩大 AI 投资的新音讯,称 2025 年围绕 AI 的全体支拨将达到 600 亿 -650 亿好意思元,比拟旧年的 380 亿 -400 亿好意思元,增长了特出 70%,从而构建起一个领有 130 万块 GPU 的超等计较机集群。
除了跟 Meta 抢开源之王的名头外,DeepSeek 正在从 OpenAI 手里抢走客户。
在比 OpenAI 低廉 30 倍的 API 价钱诱骗力之下,一些初创公司正在改革门庭。企业级 AI 代理诱导商 SuperFocus 的调处首创东谈主 Steve Hsu 认为,DeepSeek 的性能与为 SuperFocus 大部分生成式 AI 功能提供支合手的 OpenAI 旗舰模子 GPT-4 相似以至更好。" SuperFocus 可能会在畴昔几盘活向 DeepSeek,因为 DeepSeek 不错免费下载、在自家工作器上存储和运行,并将增多销售产物的利润率。"
成为更多公司的模子底座,这亦然梁文锋研究中 DeepSeek 最想占据的定位。在梁文锋看来,DeepSeek 畴昔不错只负责基础模子和前沿的革命,然后其他公司在 DeepSeek 的基础上构建 To B、To C 的业务。"若是能酿成完好的产业高卑鄙,咱们就没必要我方作念期骗。"梁文锋说谈。
国内,对 DeepSeek 的研究也在同步进行。有报谈称,字节最初、阿里通义以及智谱、Kimi 等团队,齐在积极研究 DeepSeek,字节最初以至可能在计议与 DeepSeek 张开研究合营。
在这些公司之前,雷军更是先东谈主一步挖起了 DeepSeek 的墙角。旧年 12 月,第一财经爆料称,雷军疑似开出千万年薪躬行挖来" 95 后天才青娥"罗福莉,后者是 DeepSeek-V2 开源模子的关节诱导者。畴昔,罗福莉或将供职于小米 AI 施行室,换取小米大模子团队。
挖东谈主以外,国内更犀利的竞争或将相通围绕 API 张开,"旧年国内有一批创业公司和中小企业,因为 OpenAI 断供转向了国内大模子公司,当今 DeepSeek 很有可能成为规复 OpenAI 失地的阿谁历害东谈主。"恒业成本首创东谈主合资东谈主江一臆测谈。
压力传导到了这些国内大模子公司身上。若是它们不成快速将模子恶果跟进到 R1 级别开yun体育网,客户就不免用脚投票。(转载自字母榜)
Powered by 开云(中国)Kaiyun·官方网站 - 登录入口 @2013-2022 RSS地图 HTML地图